GPU VM에서 대형 LLM 실행하기
이 문서는 Elice Cloud Infrastructure(ECI) 의 GPU 가상머신(VM) 에서 대형 언어 모델(LLM)을 실행하는 실습 가이드입니다.
ECI는 VM 생성 시 블록 스토리지 이미지 선택을 통해 GPU 실행 환경을 미리 구성할 수 있으며, 본 실습에서는 PyTorch가 사전 설치된 GPU 이미지를 사용해 추가 환경 설정 없이 바로 vLLM 기반 LLM 추론을 실행합니다.
실습 목표
이 문서를 완료하면 다음을 할 수 있습니다.
- ECI GPU VM 이미지 선택 방식 이해
- PyTorch가 포함된 GPU VM을 생성해 즉시 LLM 실행
- vLLM을 이용한 대형 LLM 로컬 추론
사전 준비 사항
- ECI 계정
- GPU 인스턴스 사용 가능 환경
- Public IP 설정
Step 1. ECI GPU VM 이미지 선택 이해
ECI에서는 VM 생성 시 블록 스토리지에 OS 이미지를 선택합니다.
GPU VM의 경우 아래 이미지 옵션을 제공합니다. (2026.01 기준)
블록 스토리지 이미지 선택 옵션
- Ubuntu 22.04
- Ubuntu 22.04 + NVIDIA 575 + CUDA 12.8 + OFED + PyTorch
- Ubuntu 22.04 + NVIDIA 575 + CUDA 12.8 + OFED + TensorFlow
- Ubuntu 22.04 + NVIDIA 575 + CUDA 12.8 + OFED + JupyterLab
본 실습에서는 vLLM + PyTorch를 사용하므로
2번 이미지 (PyTorch 포함) 옵션을 선택해야 합니다.
Step 2. GPU VM 생성 (중요 설정)
VM 생성 방법의 전체 흐름은 아�래 문서를 참고해주세요.
필수 설정 요약
1️⃣ 인스턴스 타입
- GPU 포함 인스턴스 선택
- 본 실습은 인스턴스 스펙의 경우,
NVIDIA A100 80GB PCIE + 16vCore + 192 GiB MEMORY에서 진행됐습니다.
- 본 실습은 인스턴스 스펙의 경우,
2️⃣ 블록 스토리지 설정 (중요)
- 이미지:
- Ubuntu 22.04 + NVIDIA 575 + CUDA 12.8 + OFED + PyTorch
- 용량:
- 최소 100GiB 이상 권장
LLM 모델은 용량이 매우 큽니다.
블록 스토리지 용량이 부족하면 모델 다운로드 중 오류가 발생할 수 있으므로
100GiB 이상을 반드시 설정해주세요.
3️⃣ 네트워크
- Public IP 필수
Step 3. VM 접속 및 GPU 상태 확인
VM이 실행 중인 상태에서 웹 콘솔 또는 SSH로 접속합니다.
GPU 확인
nvidia-smi
CUDA 확인
nvcc --version
정상 출력 시 다음이 확인됩니다.
- NVIDIA Driver: 575
- CUDA Version: 12.8
- GPU 모델 및 VRAM 정보 표시
만약, nvcc --version이 동작하지 않는다면 nvidia-smi에는 CUDA 12.2로 나오는데 nvcc --version이 안 됩니다. PyTorch도 12.2를 지원하지 않습니다. 문서를 참고해주세요.
Step 4. Python 환경 준비 (최소 설정)
PyTorch는 이미 설치되어 있으므로, 필요한 것은 가상환경과 vLLM 설치뿐입니다.
sudo apt update
sudo apt install -y python3-venv python3-pip
mkdir llm-vllm
cd llm-vllm
python3 -m venv .venv
source .venv/bin/activate
Step 5. vLLM 설치
pip install -U pip
pip install vllm transformers
설치 확인 (선택):
python3 - <<EOF
import torch
print(torch.cuda.is_available())
print(torch.version.cuda)
EOF
True12.8
이면 정상입니다.
Step 6. 실행할 LLM 선택
이번 실습에서는 7B급 LLM을 사용합니다.
추천 모델:
mistralai/Mistral-7B-Instruct-v0.2meta-llama/Llama-2-7b-chat-hf
Step 7. vLLM으로 LLM 실행하기
1️⃣ 실행 스크립트 생성
nano llm_infer.py
2️⃣ 코드 작성
from vllm import LLM, SamplingParams
MODEL_ID = "mistralai/Mistral-7B-Instruct-v0.2"
sampling_params = SamplingParams(
temperature=0.8,
max_tokens=128,
)
llm = LLM(
model=MODEL_ID,
trust_remote_code=True
)
prompts = [
"Explain what a large language model is in simple terms.",
"Write a short poem about cloud computing."
]
outputs = llm.generate(prompts, sampling_params)
for prompt, output in zip(prompts, outputs):
print("PROMPT:")
print(prompt)
print("\nOUTPUT:")
print(output.outputs[0].text)
print("=" * 50)
Step 8. 실행
python llm_infer.py
다음과 같은 실행화면이 나타납니다. (결과는 다를 수 있습니다.)
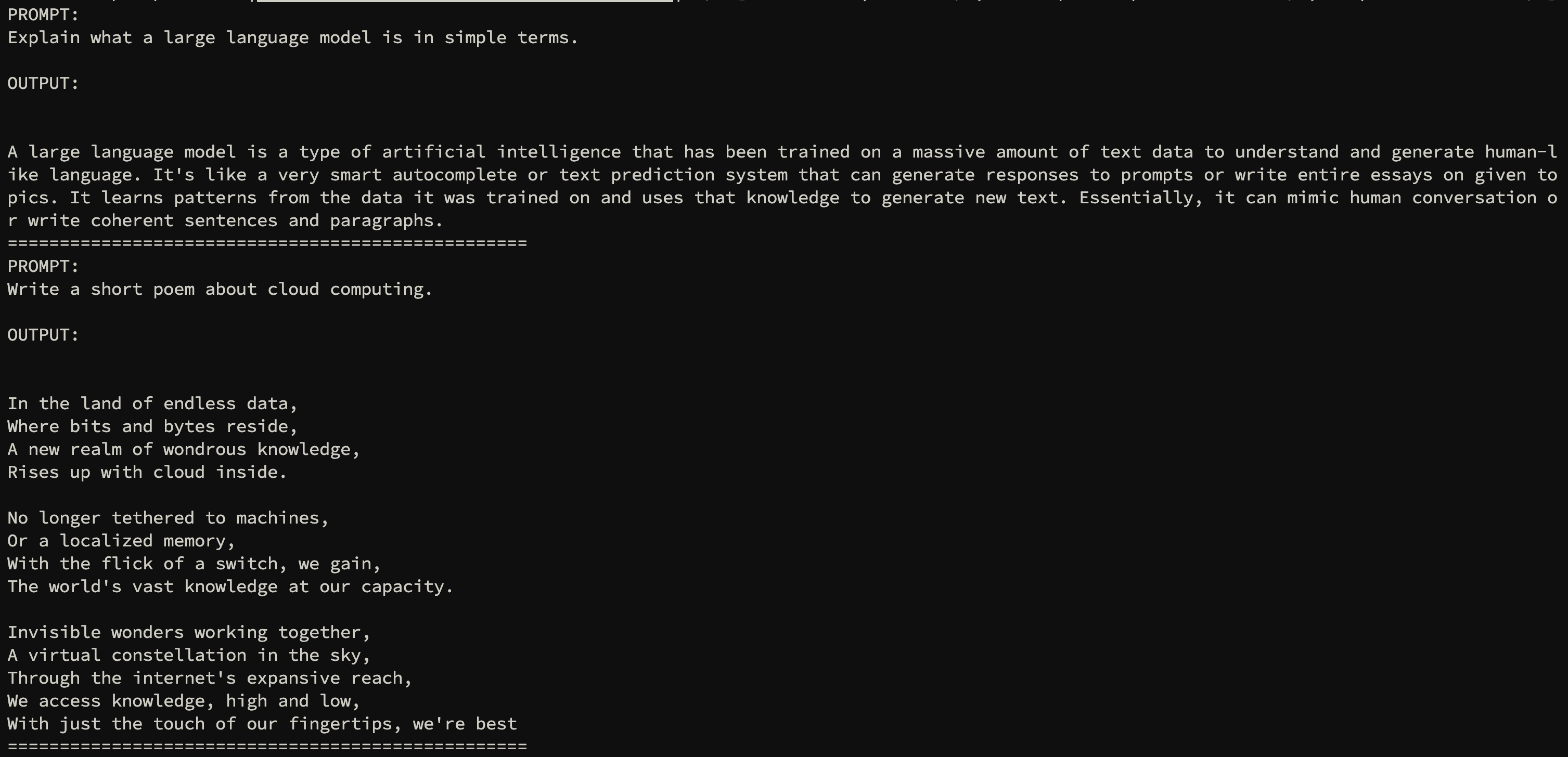
문제 해결 (Troubleshooting)
CUDA out of memory
- 더 작은 모델 선택
max_tokens값 감소- VRAM이 더 큰 GPU 인스턴스 사용
모델 다운로드 실패
- Public IP 설정 여부 확인
- 블록 스토리지 용량 확인